
The project that I’m working on has a rather spotted history for unit tests until now. There would be periods of people actually writing them, but then come unstuck when a random test failed and eventually the tests would be allowed to rot a bit, until something spurned everyone back to life again.
However, unit testing is something we, as a team, are getting better at and to aid the continual improvement of code base I turned on code coverage metrics in Team City earlier this week, and set it to fail the build if the metrics fell below a certain threshold. That way if test coverage dropped the build would fail, and since we’re also driving towards implementing a continuous delivery process failing builds will mean we can’t deploy either. This is good. It means we will not be able to deploy poor quality code.
What does code coverage on a build server get you?
Put simply, it shows you what code was covered during the automated tests run on the build server. You can then use this information to direct focus on areas that are not sufficiently tested to drive up code quality.
Turning on code coverage means that Team City will be able to display those metrics to you after the build is complete. You can drill in to the metrics to get a better understanding of what code your tests are exercising, and perhaps more importantly, what code isn’t being exercised.
When Team City builds a project it will run several build steps, at least one of which should be some sort of testing suite and you may have more if you have a mix of test types (e.g. unit tests and integration tests). The code coverage metrics are generated during the testing steps. At the end, you can examine the results just like any other aspect of the build.
This is an example of what the “overview” looks like after a build it run with code coverage turned on:

I like that it also shows the differences between this and the previous build as well as the overall numbers.
The statistic that I think is probably the most important is the statements percentage as that is unlikely to change as much as if you split out code in to separate classes or methods. It also means that you get a better idea of coverage if you have larger methods with high cyclomatic complexity or large classes.
Incidentally, splitting large methods and classes into smaller ones should make things easier to test, but I’d rather not have that impacting the metric we are using for code coverage. The number of statements remains relatively similar even after splitting stuff out and also since there so many more statements than methods or classes even if there is a slight change in the number the overall impact on the percentage metric is minimised.
If you want to drill into the detail, you can go into “full report” and see the break down by assembly. For example:

As you can see it gives a breakdown of coverage by assembly. Each of the assembly names is a link allowing you to drill in further.

Eventually you can get as far down as the individual file and this is where the power really lies. When viewing an individual file you can see individual lines of code that have been exercised in some way (in green) and ones that have not (in red).
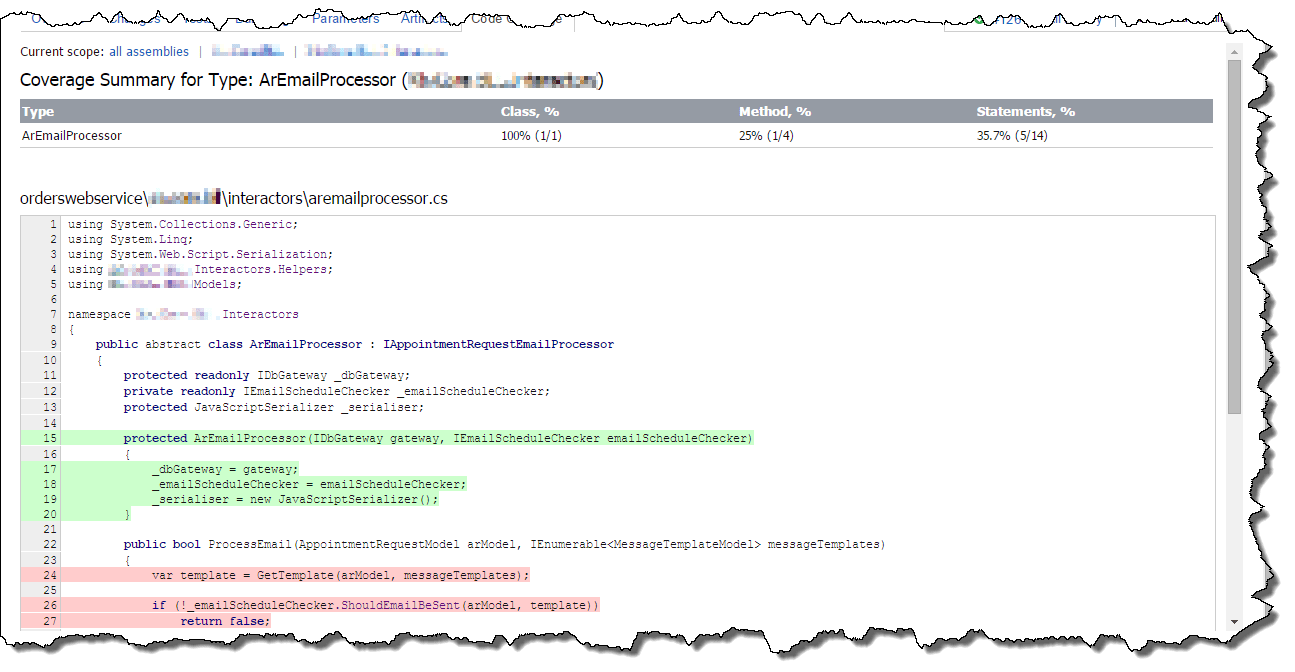
It is worth noting that just because a line is green it does not mean it was exercised well. Code Coverage is just a metrics tool. It just says something was done, not that it was correct. This is vitally important to remember. However, it is still a valuable tool to be able to see areas where there is no code coverage at all.
Setting up Code Coverage in Team City
On the Team City dashboard go to the project you are interested in, click the down arrow next to the build name and select “Edit Settings” from the menu.

On the Build Configuration Settings page, click on “Build Steps” in the side bar.

Then, find the step that performs the tests, and click edit.
Towards the bottom of the settings is an entry marked “.NET Coverage tool”. Select “JetBrains dotCover” as this is built in to Team City. You can of course choose one of the other coverage options, but you’ll have to configure that yourself.

You don’t need to enter a path to dotCover unless you are installing a different version to the one Team City has built in. (We’re using Team City 8.1 and it has an older version of dotCover, but it works well enough for what we want.)
In the filters section you need to put in details of the code you want to cover. I’ve just put in a line for all assemblies, then some lines to exclude other assemblies. I found that it sometimes picks up assemblies that were brought in via NuGet and shouldn’t be covered as it will skew your statistics. You can see the assemblies it picked up automatically by drilling into the code coverage from the overview page for the build as I showed above. I also excluded assemblies that are purely generated code, like the assembly that contains just an EDMX and the code autogenerated from it.
The basic format of the filters is:
+:assembly=<assembly-name> to include an assembly, wild cards are supported.
-:assembly=<assembly-name> to exclude an assembly, wild cards are supported.
However, you can filter on more that just the assembly level. More detail is available from Team City’s online help.
Once you’ve set this up hit “Save” at the bottom of the page.
You can now perform a test build to see how it works by pressing “Run…” at the top of the page.
When the run is complete you can view the results by clicking on the build on the main page.

From the overview you can drill in and see the assemblies that were picked up, as shown above. If there are any assemblies that shouldn’t be there (e.g. third party libraries) you can then add them to the filter in the build step configuration to make sure they are excluded from the code coverage reports.
Finally, to ensure that you don’t fall backwards and ensure that you maintain the code coverage above a certain threshold you can add a failure condition to the Build Configuration Settings.
Go back to the build settings page, and then to the “Failure Conditions” section.

Then press “+ Add failure condition” and a dialog will pop-up.

Select “Fail build on metric change” from the drop down.
Then, in the “Fail build if” section, select “its” “percentage of statement coverage”, “Is compared to” “constant value” “is” “less” than <percentage-value> “default units for this metric”
For <percentage-value> take the value form your first reference build subtract about half a percent then round down. There will naturally be minor fluctuations up-and-down on each build and you don’t want to be too strict either.
Then press “Save”. The page will refresh and you’ll see the failure condition added to the table at the bottom of the page.

Now each time this build is run it will run code coverage and if it drops below the threshold it will fail the build.






